


April 29, 2016
Split Testing
Running controlled experiments (A/B tests) is a core discipline of conversion rate optimization. If you’re running tests, that’s awesome. But you may be messing them up, and therefore making decisions based on faulty data - not awesome. Not to worry though, we all make mistakes (even the experts). Contrary to popular belief, it’s not as easy as learning how to use A/B testing software then running down a blog post of 101 Things You Can A/B Test Right Now (written by someone who’s likely never ran a test)… So you’re going to stumble, but why not mitigate some of those risks by learning from mistakes others (I) have made. Here are some things I wish I knew when I started in optimization…
1. Most conversion rate optimization case studies are BS
Case studies are entertaining. Instead of doing the heavy lifting of analyzing your own data and finding opportunity areas, you can just copy someone else’s test. Hey, they got a 200% lift, right? Not so fast. There are a couple things people don’t realize about case studies. First, case studies are contextual. Even if someone got a big uplift, that’s not an indicator that it will work for you. Your audience is specific to you and so are your problems. Second, it’s almost a sure thing that the case study you’re reading isn’t accurate. Either the author didn’t include all of the data or the numbers are so flawed that the case study is actually damaging to the industry. In the first case (full numbers not being present), well, you’ll simply have to be discerning. Non-disclosures prevent a lot of good information from entering the public realm of the internet. But there are ways to work around this if you’re authoring a case study. Justin Rondeau from Digital Marketer wrote up a great piece on how to do that (and how to tell whether a case study is BS or not). The second case is because the author is neglecting statistics. Their results are a false positive. Go look at some of the case studies on Leadpages’ blog or the earlier Which Test Won examples - they’re almost all tenuous results based on samples of <100. You’re not learning anything from these case studies. [caption id=“attachment_4256” align=“aligncenter” width=“690”] As likely as your 300% lift. (Source)[/caption] (Fun aside: one of the first articles I’d written for ConversionXL cited one of the offending sites. I got yelled at by Peep and learned pretty fast to be more critical :))
As likely as your 300% lift. (Source)[/caption] (Fun aside: one of the first articles I’d written for ConversionXL cited one of the offending sites. I got yelled at by Peep and learned pretty fast to be more critical :))
2. Don’t stop a test early (or at significance)
This is one of the biggest mistakes we see people make when they first start testing. A large amount of our blog posts on A/B testing and statistics attempt to dispel this myth. Of course, this makes sense. It’s common practice to trust the results of a controlled experiment when they hit 95% statistical significance. There are a few problems with this in A/B testing though, one of the main problems is you’re not accounting for a representative sample. Let me explain. If you start a test on Monday and end it (with significance) on Friday, you didn’t account for weekend buyers and weekend buying habits, which might be much different than any given day of the week. That’s just one problem. Another is that people think they can “spot a trend.” Nope - total BS. Test results tend to go crazy until the sample becomes sufficient to even out the kinks. Plus, things like regression to the mean often kick in. What if you’d stopped the following test early? [caption id=“attachment_4257” align=“aligncenter” width=“690”]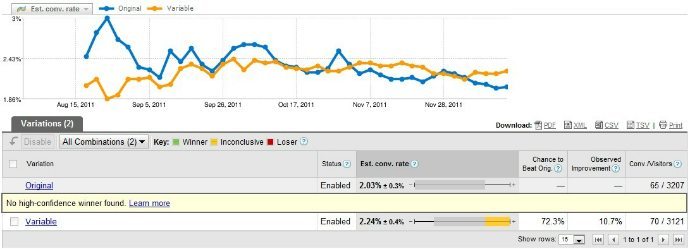 Source[/caption] The correct way to go about it is to pre-calculate your minimum needed sample size (no penalty for a bigger sample size), and testing for one (better still two) full business cycles – so the sample would include all weekdays, weekends, various sources of traffic, your blog publishing schedules, newsletters, phases of the moon, weather and everything else that might influence the outcome.
Source[/caption] The correct way to go about it is to pre-calculate your minimum needed sample size (no penalty for a bigger sample size), and testing for one (better still two) full business cycles – so the sample would include all weekdays, weekends, various sources of traffic, your blog publishing schedules, newsletters, phases of the moon, weather and everything else that might influence the outcome.
3. If you don’t have a process, you don’t know what you’re doing
There’s no way to ‘hack’ your way to optimization success. Button colors don’t usually make for drastic results, and running down a list of tactics is an inefficient waste of time. Look, there are many different optimization philosophies. I don’t think there’s been a definitive conclusion on which one works best. But it has been shown that optimization teams with a documented process are more successful, and they’re more likely to place higher priority on optimization and give it more budget. For our process, we run through the ResearchXL framework - a high-performing research and prioritization framework for testing.  There’s also Andrew Anderson’s discipline-based methodology. Whatever you do, it’s important that you implement (and optimize) your optimization framework. Make sure you’re efficient from an organizational standpoint, not just a test-by-test one.
There’s also Andrew Anderson’s discipline-based methodology. Whatever you do, it’s important that you implement (and optimize) your optimization framework. Make sure you’re efficient from an organizational standpoint, not just a test-by-test one.
4. You need to know a lot about a lot to optimize
Some optimizers come from an analytics background. Some from UX. Others from psychology, engineering, or marketing. To be an optimizer, you need to know a lot about a lot. Some of the skills I’ve dived into include:
- Statistics
- Analytics
- User experience
- Market research
- Psychology
- Copywriting
- Project management
And then there’s the tool-specific skills (which is really the easiest to learn and the least important). Someone running experiments must have a natural curiosity about the world (otherwise they probably wouldn’t be running experiments anyway), so it’s only normal that they fall into a role like this. It’s perfect for an erudite, data-driven, creative person.
5. You can’t usually test with low traffic (but you can still optimize)
Testing is a huge part of optimization. It’s also the sexy part (there’s a reason there are so many case studies out there). So it’s always disappointing to realize that if you have low traffic, you probably can’t take part in the fun. But, you can still optimize. Testing is a big part of optimization, but not the whole thing. To optimize low traffic sites, you can do:
- Usability testing
- Heat maps
- Expert heuristic analysis
- Sequential testing
If you have a sufficient level of traffic, sometimes you can run a radical A/B test that has a large enough effect to be detected. But that’s when you’re really shooting for the moon. You’re probably better off focusing on product and acquisition for now.
6. Small changes produce small results (usually)
We can all point to a case study where changing a button color resulted in a huge lift, but it’s usually not the case. Sure, small changes can have big impact (like adding microcopy to improve UX, fixing bugs that incur usability problems, etc). But most of the time, if you’re changing “your” to “my” in button copy or changing its color or whatever other fun idea you have, it’s going to result in an inconclusive test. We’ve all been there. Groove wrote about some of their meaningless tests and showed they didn’t move the needle at all: 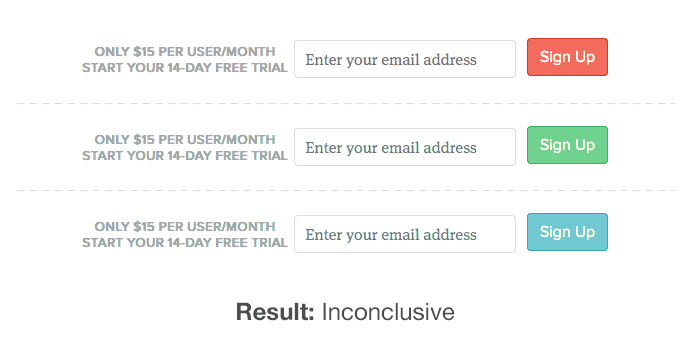 While huge companies, like Amazon or Google – with their millions of visitors each day – can run statistics with lots of power for measuring significance on small cosmetic changes, smaller companies need to hone in on the big wins instead. Another example comes from Alex Bashinsky, co-founder of Picreel. They were trying to maximize the impact of their social proof section, so they tested colored logos with links from various media mentions versus grey logos without links. Version A:
While huge companies, like Amazon or Google – with their millions of visitors each day – can run statistics with lots of power for measuring significance on small cosmetic changes, smaller companies need to hone in on the big wins instead. Another example comes from Alex Bashinsky, co-founder of Picreel. They were trying to maximize the impact of their social proof section, so they tested colored logos with links from various media mentions versus grey logos without links. Version A:  Version B:
Version B:  The results?
The results? 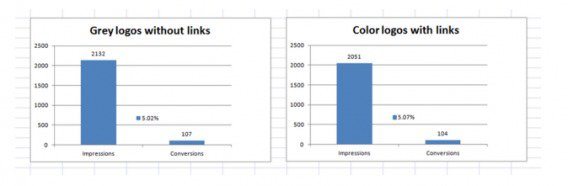 Didn’t move the needle. Visitors could care less about logo color. If you’ve been hitting a rough patch of inconclusive tests, you’re probably 1) going to lose organizational support for testing fast and 2) probably running tests that aren’t changing much. If you have an optimization process (as mentioned above), you’ll likely discover and prioritize tests that actually matter. Then there are the more human elements of creativity, boldness, and discovery. As Kyle Rush says you should, “Err on the side of testing the extreme version of your hypothesis. Subtle changes don’t usually reach significance as quickly as bigger changes. For the A/B test you want to know if your hypothesis is correct. Once you know that, you can fine tune the implementation of the hypothesis.” Instead of going from small test to small test, your conversion rate optimization should be a process. There many frameworks out there, but I suggest checking out our ResearchXL model to gather and prioritize insights.
Didn’t move the needle. Visitors could care less about logo color. If you’ve been hitting a rough patch of inconclusive tests, you’re probably 1) going to lose organizational support for testing fast and 2) probably running tests that aren’t changing much. If you have an optimization process (as mentioned above), you’ll likely discover and prioritize tests that actually matter. Then there are the more human elements of creativity, boldness, and discovery. As Kyle Rush says you should, “Err on the side of testing the extreme version of your hypothesis. Subtle changes don’t usually reach significance as quickly as bigger changes. For the A/B test you want to know if your hypothesis is correct. Once you know that, you can fine tune the implementation of the hypothesis.” Instead of going from small test to small test, your conversion rate optimization should be a process. There many frameworks out there, but I suggest checking out our ResearchXL model to gather and prioritize insights.
7. The gold is in the segments
As Avinash Kaushik said, “all data in aggregate is crap.” The gold, then, is in the segments. Whether you’re trying to find correlative metrics to optimize your user onboarding (finding your users’ wow moment), or you’re trying to find funnel leaks, it’s important to learn about analytics segmentation. In fact, the ability to slice and dice your Google Analytics data (or whatever you’re using) is the difference between mediocre, surface-level insights and meaningful, useful analysis. Sometimes, too, if you’re running an A/B test and the results are inconclusive, you can find some discrepancies in different segments. That’s why integrating your analytics tool with your testing tool is so important - post-test analysis in GA is much more robust than in your testing tool. For example, say you got a lift in returning visitors and mobile visitors, but a drop for new visitors and desktop users – those segments might cancel each other out, and it seems like it’s a case of “no difference” - but you analyze your test across different segments and see there are differences. To start, you should look at test results at least on these segments (make sure each segment has adequate sample size):
- Desktop vs Tablet/Mobile
- New vs Returning
- Traffic that lands directly on the page you’re testing vs came via internal link
If your treatment performed well for a specific segment, it’s time to consider a personalized approach for that particular segment.
8. Build a culture of experimentation and the rest (should) fall into place
The effectiveness of your optimization program is primarily a function of your top down organizational culture. So while, yes, it’s imperative to know something about stats, have a good process in place, etc, it’s most important to build a culture of testing and experimentation. Thankfully, more and more organizations seem to be swaying towards data-driven decision making and experimentation-based cultures - which is much better than the previous idea that executives (HiPPOs) hold some sort of divine clairvoyance when it comes to decision making. You’d be surprised how many marketers still lead with their hearts, falling for their own biases and logical fallacies, because they don’t think in terms of exploration or discovery. Building a culture of experimentation could be a book of it’s own, but here’s a good post to get you thinking about it.
Conclusion
There’s no substitute for experience. Start running tests as soon as you can. You may (you will) make mistakes, but you’ll learn. That’s what it’s all about. You can deep dive into many of the topics I’ve brought up here, but even if you keep it high-level, you’ll still know more than most marketers. Now go test stuff and make more money.










{kind=link}